







Xin chào, bài viết dưới đây hướng dẫn bạn có thể kéo HTML, CSS, JS của một website về chỉ với một dòng lệnh.
Tôi vừa lên themeforest và thấy một giao diện rất là hay ho đó là : http://react.pixelstrap.com/multikart/vegetables

Đầu tiên tôi sẽ lấy toàn bộ html về chỉ với một câu lệnh :
wget –no-clobber –convert-links –random-wait -r -p -E -e robots=off -U mozilla http://react.pixelstrap.com/multikart/vegetables
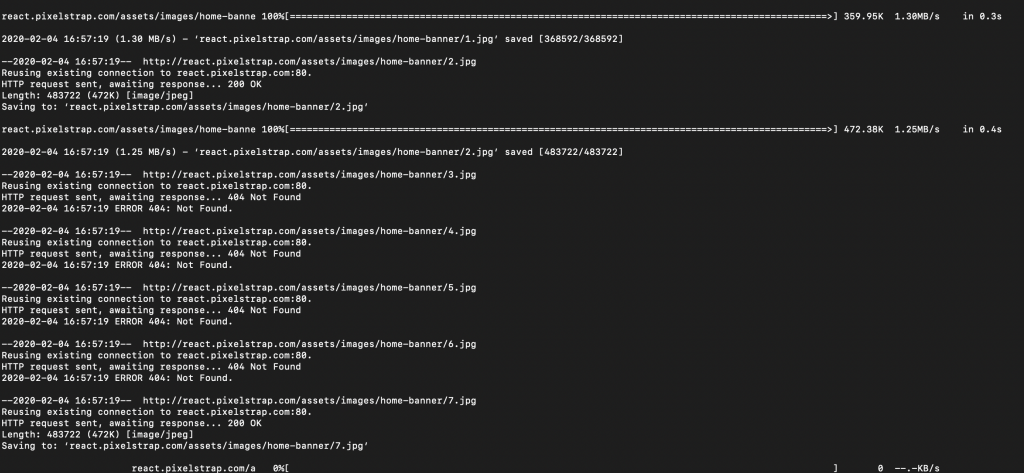
Terminal (bash) đang lấy toàn bộ resource của HTML này về.
Ta da, vậy là toàn bộ resource của trang này đã có mặt ở trên máy của tôi, bao gồm cả html, js, css và cả ảnh.
Nhưng có gì đó sai sai, khi chạy website lên lỗi té re luôn:
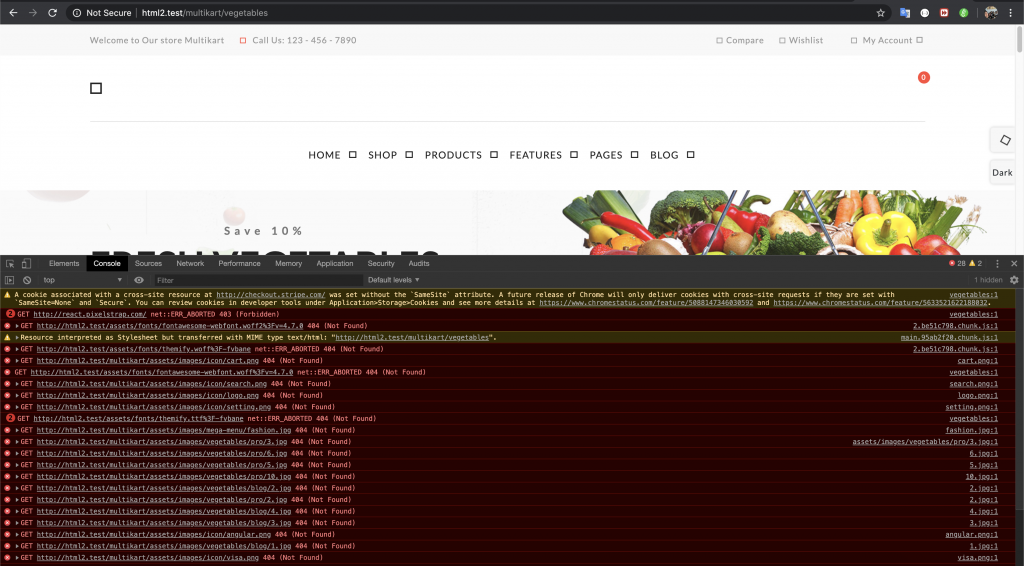
Tôi quyết định sử dụng thêm một công cụ mạnh mẽ hơn đó là php với phương trâm cần gì lấy nấy.
Tôi sẽ tạo một files index.php ở thư mục gốc với nội dung như sau:
<?php
// die;
$actual_link = (isset($_SERVER['HTTPS']) && $_SERVER['HTTPS'] === 'on' ? "https" : "http") . "://{$_SERVER['HTTP_HOST']}{$_SERVER['REQUEST_URI']}";
$origin_link = str_replace( '.test', '.io', "$actual_link");
// print_r($actual_link);
// print_r($origin_link);
// print_r(( $_SERVER['REQUEST_URI'] ));
$array = (explode("/", $_SERVER['REQUEST_URI']));
unset($array[count($array) - 1]);
$path = join("/", $array);
$path = ltrim( $path, "/");
echo ("mkdir -p '$path'");
echo exec("mkdir -p '$path'");
chdir($path);
echo getcwd() . "\n";
echo exec("wget '$origin_link'");
die;
Sau khi truy cập lại đường dẫn http://html2.test/multikart/vegetables. Ta lấy được hầu hết ảnh với css với js về luôn.
Almost done! Chỉ còn một chút files font có ký tự đặc biệt do wget sinh ra.

Ta find and replace toàn bộ phần %3…. ra khỏi project rồi truy cập lại đường dẫn http://html2.test/multikart/vegetables.
Xong. Đây là kết quả thu được :

 (4 lượt thả tim)
(4 lượt thả tim)




